Why Cloud Native and Analysis-Ready-Cloud-Optimized (ARCO) Data for Scalable Cloud Computing and Data Analytics to Support Open Science
NOAA Enterprise Data Management Workshop May 2024
Volume of data
Users can no longer manage analysis on a single machine.
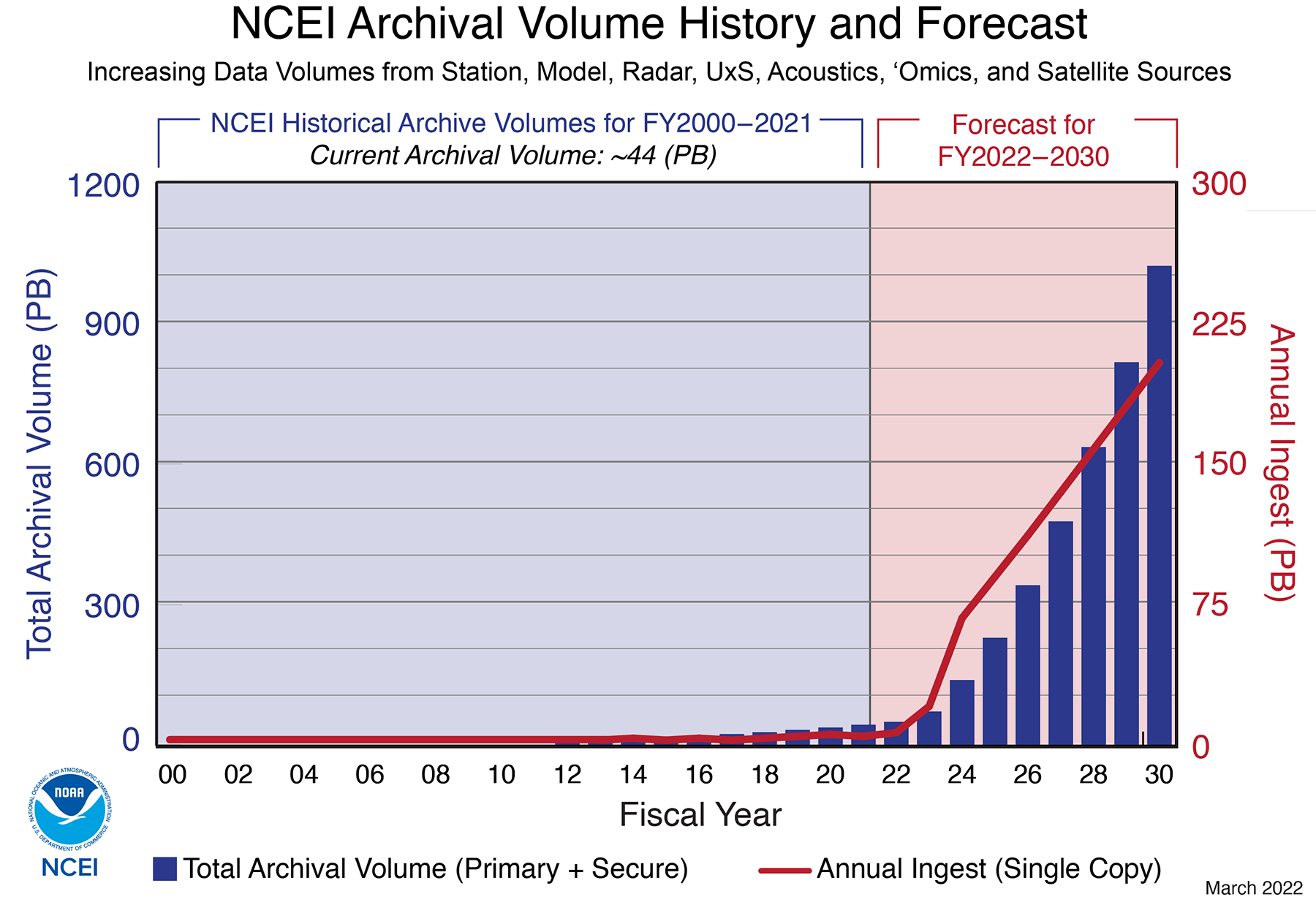
image source: https://www.ncei.noaa.gov/news/ncei-archive-growth-and-change
Cloud-native workflows enable reproducible, scalable analysis.
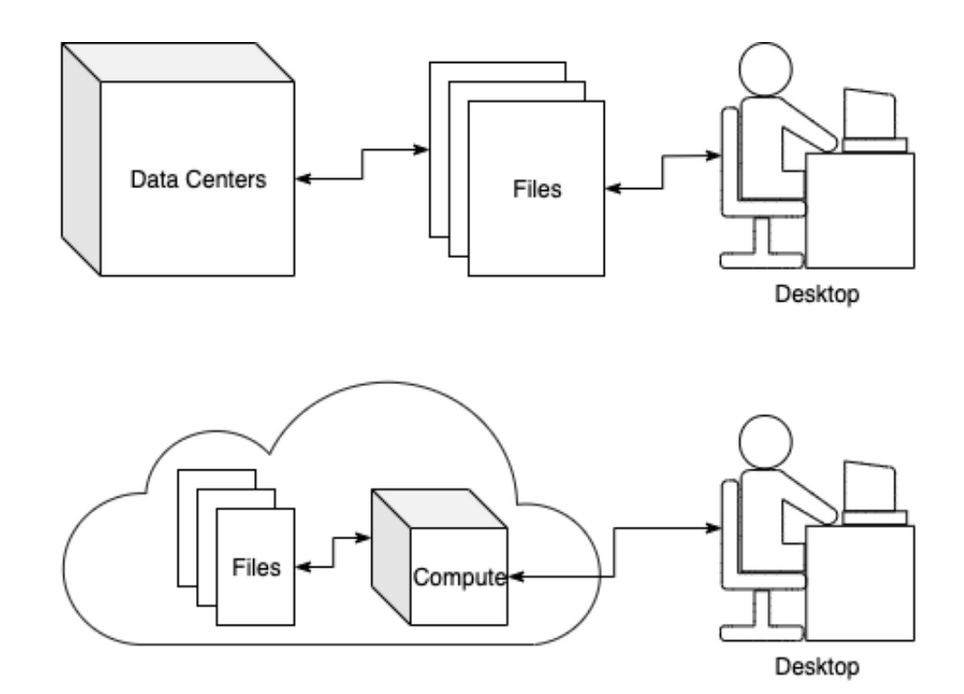
- End-to-end science workflows can be performed in the cloud: from data discovery, to processing, to analytics and visualization.
- This is possible via direct data access to cloud-optimized data by users or services.
- Cloud-native workflows promote:
- scalability,
- reproducibility, and
- and online publishing (executable papers).
What Makes Cloud-Optimized Challenging?
- Just putting files in the cloud is not enough.
- There is no one size fits all approach.
- Based on data type – raster, vector or point cloud – Earth observation data may be processed into different formats and stored in a variety of data structures.
- Optimization also depends on the user: users have to learn new tools and access needs differ.
- BUT, there are concepts that all cloud-optimized access has in common.
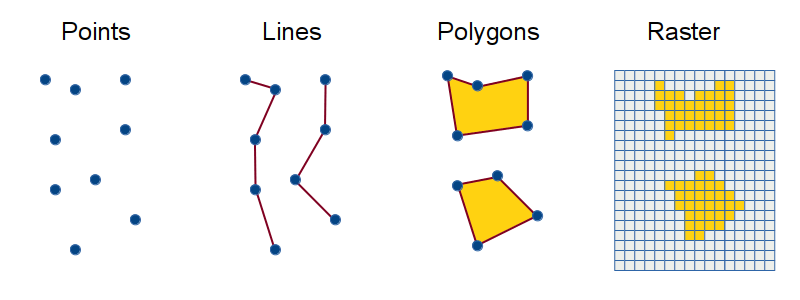
image source: ui.josiahparry.com/spatial-analysis.html
Why minimize the number of requests?
- Because, when accessing data over the internet, such as when data is in cloud storage, latency is high when compared with local storage so it is preferable to fetch lots of data in fewer reads.
- If you can load all metadata in a few reads, those can be used to make requests for a cloud-native dataset.
- A cloud-native dataset is one with small addressable chunks via files, internal tiles, or both.

image credit: https://wiki.earthdata.nasa.gov/display/ESO/Zarr+Format
How does it work?
- Data in cloud storage must be accessible over HTTP using range requests. Object storage supports this.
- HTTP range requests support lazy access and intelligent subsetting.
- Integrates with high-level analysis libraries and distributed frameworks.
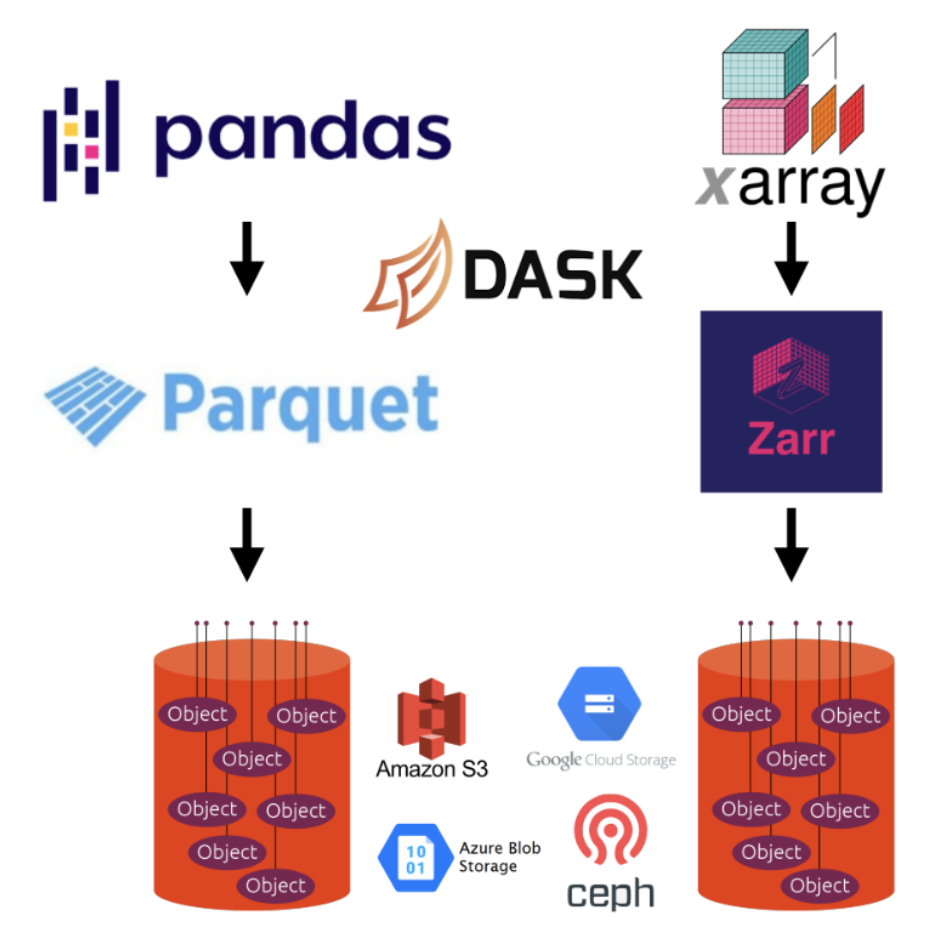
Formats by Data Type
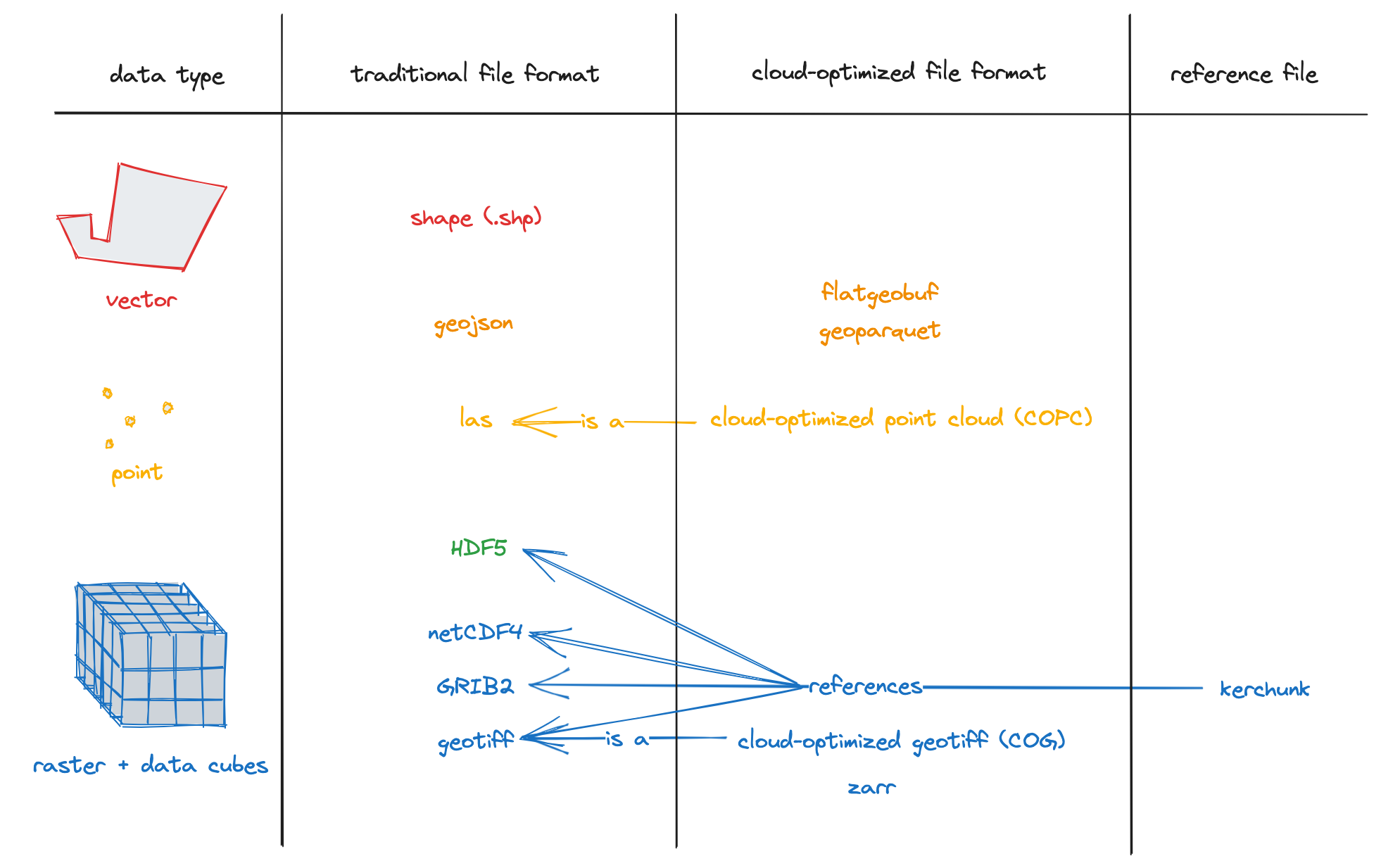
What are COGs?
- COGs are raster data representing a snapshot in time of gridded data, for example digital elevation models (DEMs).
- COGs are a de facto standard, with an Open Geospatial Consortium (OGC) standard under review.
- The standard specifies conformance to how the GeoTIFF is formatted, with additional requirements of tiling and overviews.
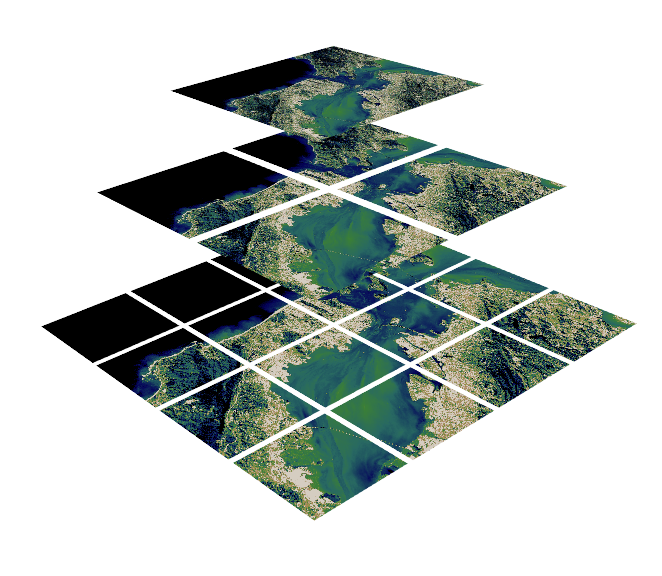
image source: https://www.kitware.com/deciphering-cloud-optimized-geotiffs/
What are COGs?
- COGs have internal file directories (IFDs) which are used to tell clients where to find different overview levels and data within the file.
- Clients can use this metadata to read only the data they need to visualize or calculate.
- This internal organization is friendly for consumption by clients issuing HTTP GET range request (“bytes: start_offset-end_offset” HTTP header)

image source: https://medium.com/devseed/cog-talk-part-1-whats-new-941facbcd3d1
What is Zarr?
- Zarr is used to represent multidimensional raster data or “data cubes”. For example, weather data and climate models.
- Chunked, compressed, N-dimensional arrays.
- The metadata is stored external to the data files themselves.
- Zarr data is often reorganized and compressed from it’s original format into many files which can be accessed according to which chunks the user is interested in.
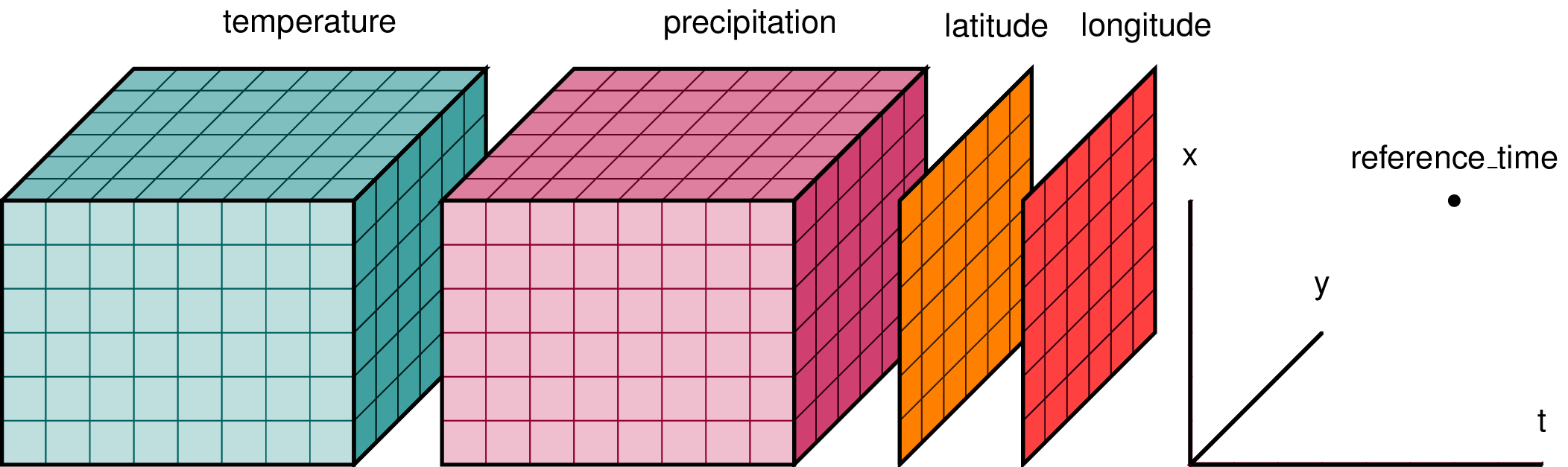
image source: https://xarray.dev/
What is Kerchunk?
- Kerchunk is a way to create Zarr metadata for archival formats, so that you can leverage the benefits of partial and parallel reads for archives in NetCDF4, HDF5, GRIB2, TIFF and FITS.
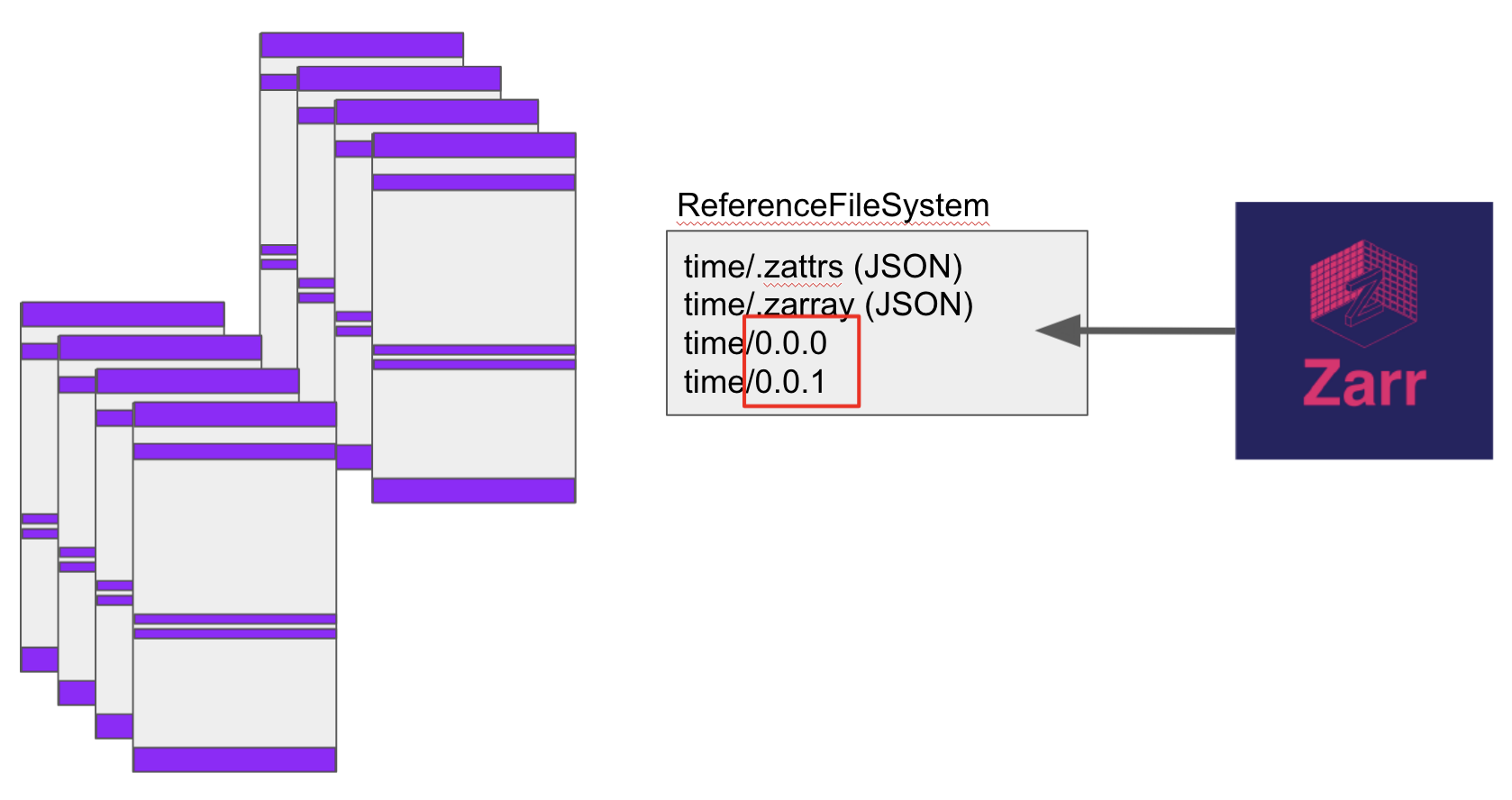
image source: https://fsspec.github.io/kerchunk/detail.html
COPC (Cloud-Optimized Point Clouds)

image source: https://copc.io/
- Point clouds are a set of data points in space, such as gathered from LiDAR measurements.
- COPC is a valid LAZ file.
- Similar to COGs but for point clouds: COPC is just one file, but data is reorganized into a clustered octree instead of regularly gridded overviews.
FlatGeoBuf
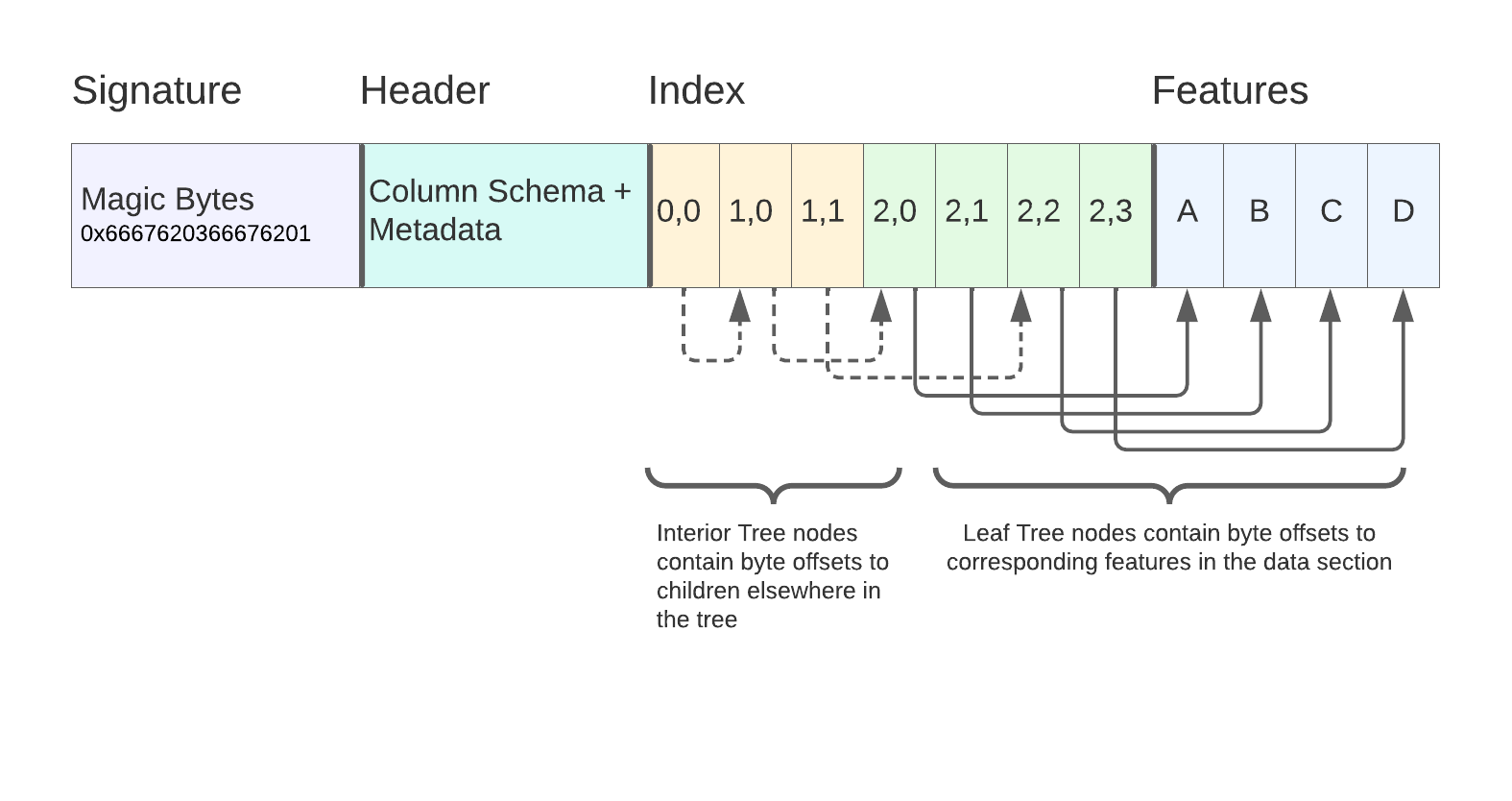
- Vector data stored as rows representing points, lines, or polygons with an attribute table.
- FlatGeobuf is a binary encoding format for geographic data using flatbuffers and stored as a single file.
- A row-based streamable-spatial index optimizes for remote reading.
- Learn more: https://github.com/flatgeobuf/flatgeobuf, Kicking the Tires: Flatgeobuf
image source: https://worace.works/2022/02/23/kicking-the-tires-flatgeobuf/
Geoparquet
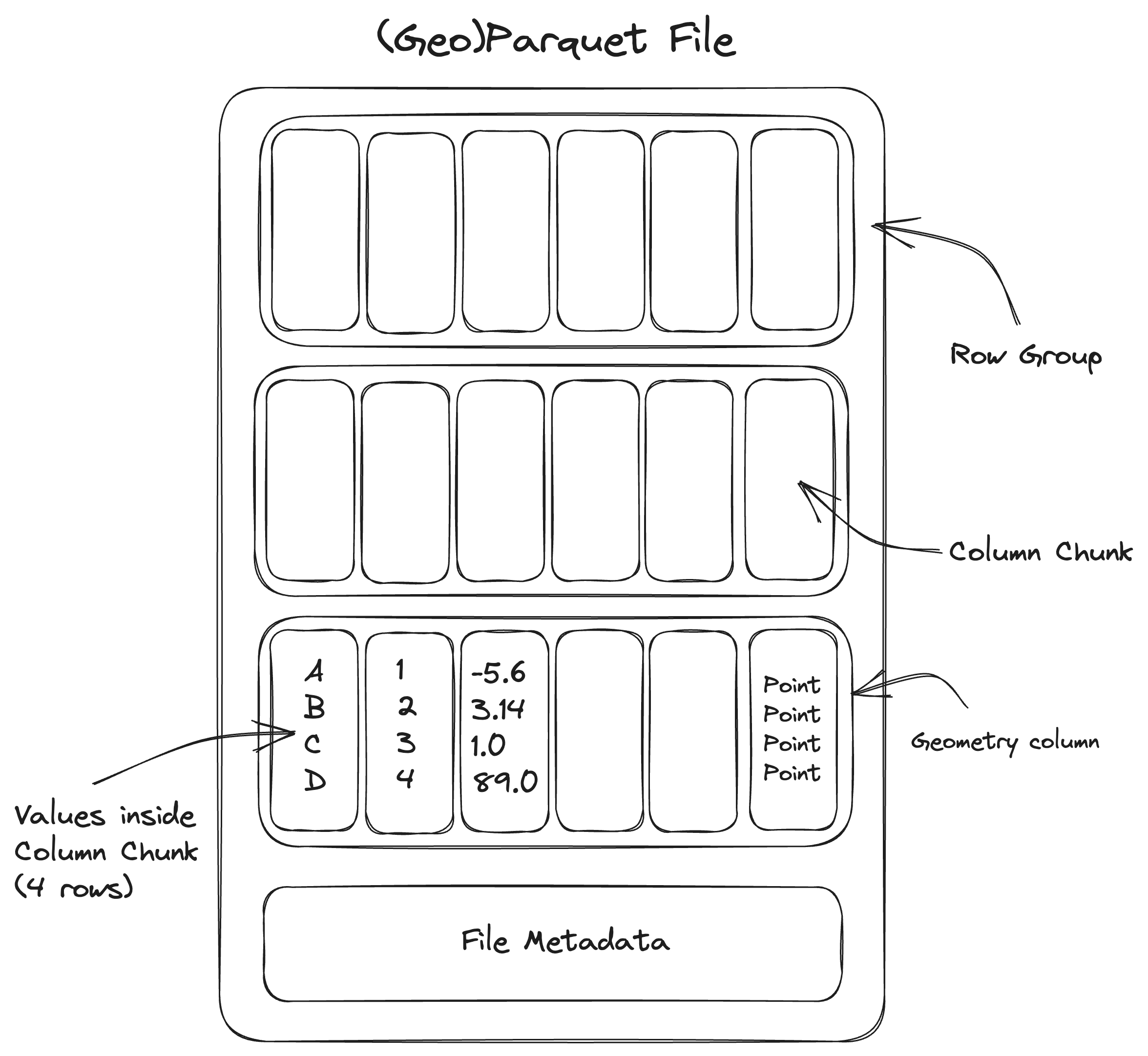
- Vector data is traditionally stored as rows representing points, lines, or polygons with an attribute table
- GeoParquet defines how to store vector data in Apache Parquet, which is a columnar storage format (like many cloud data warehouses). “Give me all points with height greater than 10m”.
- Learn more: https://github.com/opengeospatial/geoparquet
image source: https://www.wherobots.ai/post/spatial-data-parquet-and-apache-sedona